Created: 2022-07-12
Process Automation using Power Automate and Python
Created: 2022-07-12
Our client received a large number of faxes (converted to PDFs) which had to be manually forwarded to customers after identifying their IDs and looking up contact details in a CRM.
Solution
- Used Power Automate to trigger on incoming emails.
- Forwarded attachments to a Python WebApp on GCP Cloud Run.
- WebApp used Pillow and Tesseract OCR to extract customer IDs.
- Queried MySQL database for dispatch info.
Architecture
Our automation solution utilized Power Automate, formerly known as Flow to act on incoming emails. Said emails were then dispatched to a custom-built WebApp hosted in GCPs CloudRun in order to utilize the client’s existing GCP infrastructure and to minimize costs.
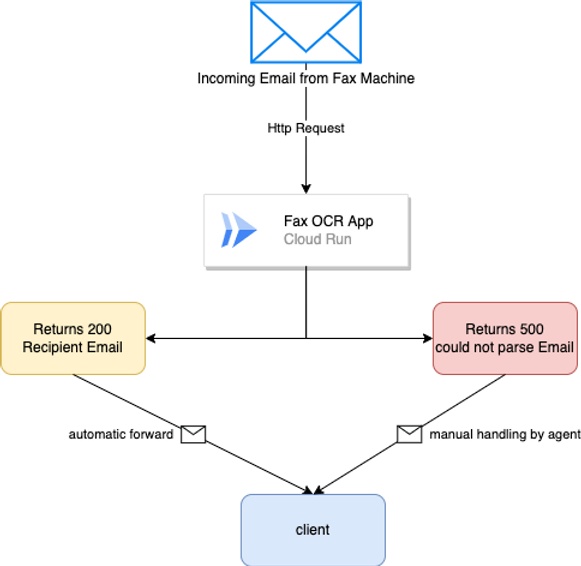
Implementation
The WebApp itself is a containerized web server written in Python which utilizes both Pillow for Image Manipulation and the Tesseract OCR library for dealing with extracting the client ID from our incoming PDF documents.
def processPDF(infile,**kwargs):
text = None
PDF_file = infile
'''
Part #1 : Converting PDF to images
'''
log.info("calling processPDF")
# Store all the pages of the PDF in a variable
pages = convert_from_path(PDF_file, 500)
# Counter to store images of each page of PDF to image
image_counter = 1
# Iterate through all the pages stored above
for page in pages:
filename = "page_"+str(image_counter)+".jpg"
page.save(filename, 'JPEG')
image_counter = image_counter + 1
'''
Part #2 - Recognizing text from the images using OCR
'''
# Variable to get count of total number of pages
filelimit = image_counter-1
# Iterate from 1 to total number of pages
for i in range(1, filelimit + 1):
filename = "page_"+str(i)+".jpg"
img = Image.open(filename)
enhancer = ImageEnhance.Contrast(img)
enhanced_img = enhancer.enhance(float(getenv('PIL_CONTRAST', 40))) # enhance contrast
enhancer = ImageEnhance.Sharpness(enhanced_img)
enhanced_im = enhancer.enhance(float(getenv('PIL_SHARPNESS', 40))) # enhance sharpness
text = str(((pytesseract.image_to_string(enhanced_im))))
matched_id = None
log.debug(text)
for i, match in enumerate(re.finditer("P\d\d\d\d\d",text)):
#print(i,match.group())
matched_id = match.group().replace("P","")
log.debug("cleanup: removing file we just created.")
os.remove(filename)
os.remove(PDF_file)
return matched_id
Handler code
We wrap the processPDF method in a handleFile method which performs some image manipulation and extracts the customer data from the clients' MySQL database:
def handleFile(data):
''' d is dictionary '''
# d contains: name, content (binary)
log.debug("entering handleFile")
tmpname = "/tmp/{n}".format(n=os.path.basename(data['name']))
with open(tmpname,'wb') as f:
base64_string = data['content']#.encode('utf-8')
base64_bytes = base64.b64decode(base64_string)
f.write(base64_bytes)
text = processPDF(tmpname)
log.info(f"matched text: {text}")
# text is now a property ID, try to reverse query SQL DB to check.
if text is None:
return (500,"could not parse")
else:
try:
recordId = lookupRecordId(text)
except Exception as err:
log.error(err)
log.error("could not find a matching record ID")
recordId = -1
return (200,recordId)
The above method processPDF is then used in a web server using the package.
import http.server, socketserver, os, json, re, base64, yaml
class CustomRequestHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
with open('./index.html', 'rb') as f:
log.info("received GET request")
self.send_response(200)
self.send_header('Content-Type', 'text/html; charset=utf-8')
self.end_headers()
self.wfile.write(f.read())
def do_POST(self):
# Doesn't do anything with posted data
content_length = int(self.headers['Content-Length']) # <--- Gets the size of data
log.debug(f"size content: {content_length}")
post_data = self.rfile.read(content_length) # <--- Gets the data itself
d = json.loads(post_data)
#print(d)
rc, msg = handleFile(d)
self.send_response(rc, msg)
self.send_header('Content-Type', 'text/html; charset=utf-8')
self.send_header('Content-Location',msg)
self.end_headers()
def do_HEAD(self):
with open('./index.html', 'rb') as f:
self.send_response(200)
self.send_header('Content-Type', 'text/html; charset=utf-8')
self.end_headers()
self.wfile.write(f.read())
httpd = socketserver.TCPServer(("", int(PORT)), CustomRequestHandler)
print(f"Python web server listening on port {PORT}...")
httpd.serve_forever()
Deployment
Packaged in a Docker container using Python, Pillow, Tesseract, pdf2image, and Google Cloud Logging. Deployed via Cloud Run for low-maintenance infrastructure.
FROM ubuntu:18.04
RUN apt-get update && apt-get install -y software-properties-common && add-apt-repository -y ppa:alex-p/tesseract-ocr
RUN apt-get update && apt-get install -y tesseract-ocr-eng python-pip
RUN apt-get install -y tesseract-ocr poppler-utils
RUN apt-get update \
&& apt-get install -y python3-pip python3-dev python-yaml\
&& cd /usr/local/bin \
&& ln -s /usr/bin/python3 python \
&& pip3 install --upgrade pip
RUN mkdir /home/work
WORKDIR /home/work
RUN pip install Pillow
RUN pip install pytesseract
RUN pip install pdf2image
RUN pip install pyyaml
RUN pip install pymysql
RUN pip install --upgrade google-cloud-logging
ADD https://github.com/tesseract-ocr/tessdata/raw/master/eng.traineddata /usr/local/share/eng.traineddata
# enable storage driver
ENV TESSDATA_PREFIX="/usr/local/share/"
WORKDIR /opt/app/
EXPOSE $PORT
COPY . /opt/app/
ENTRYPOINT ["python", "./server.py"]
This reduced human error and accelerated response time for dispatching messages to customers.